assistants api Agency Swarm with Third Party and Open Source Models I have recently been answering a bunch of questions from agency swarm users looking to leverage Astra Assistants. Agency swarm is built ontop of OpenAI's Assistants API and folks have been voicing desire to use it with other model providers and with open source models.
openai What is Astra Assistants Astra Assistants is a drop in replacement for OpenAI's Assistants API that supports third party LLMs and embedding models and uses AstraDB / Apache Cassandra for persistence and ANN. You can use our managed service on Astra or you can host it yourself since it's open source.
astra Connecting to Astra from DataGrip via JDBC A few users have been asking me lately about connecting to DataStax Astra from different developer tools. As a result I am planning to do a series of quick posts around these starting
akka-persistence-cassandra Astra and Akka-Peristence I've been chatting with a few folks that run akka-persistence backed by cassandra using either the akka-persistence-cassandra project directly or via the Lagom micro services framework. These folks are often big fans of
DataStax Proxy for DynamoDB™ and Apache Cassandra™ - Preview Yesterday at ApacheCon, our very own Patrick McFadin announced the public preview of an open source tool that enables developers to run their AWS DynamoDB™ workloads on Apache Cassandra. With the DataStax Proxy
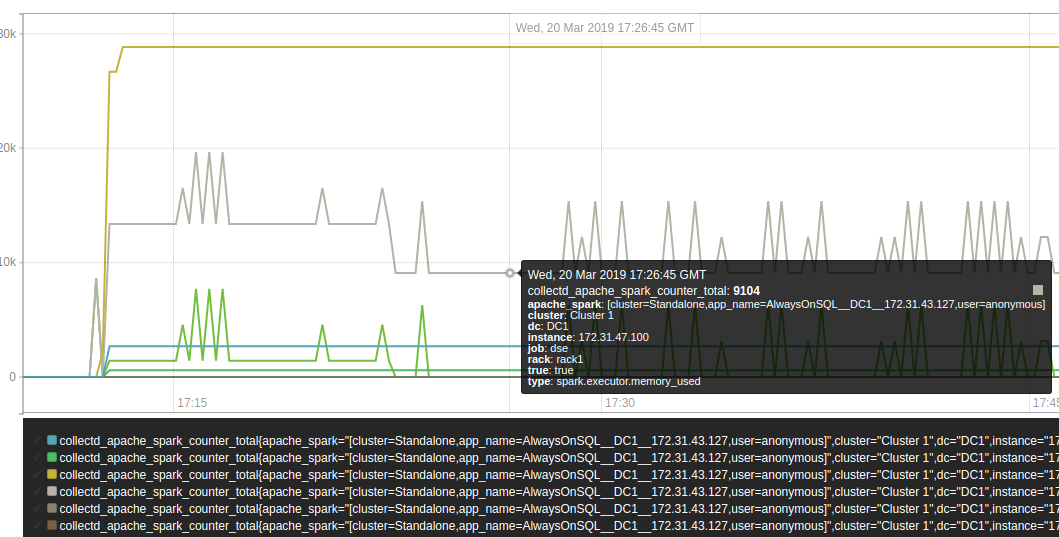
Integrate Spark Metrics using DSE Insights Metrics Collector Metrics and visibility are critical when dealing with distributed systems. In the case of DSE Analytics we are interested in monitoring the state of the various Spark processes (master, worker, driver, executor) in
DSE Gremlin Queries: Good, Better, Best Why Some Gremlin Queries Run Faster than Others Intro With great power comes great responsibility. --Spiderman's Uncle The Gremlin language gives users great power in the form of traversal expressivity. With the dozens
Large Graph Loading Best Practices: Tactics (Part 2) The previous post introduced DSE Graph and summarized some key considerations related to dealing with large graphs. This post aims to: describe the tooling available to load large data sets to DSE Graph
Large Graph Loading Best Practices: Strategies (Part 1) This post is an intro to DSE Graph with a focus on the strategies that should be used to load large graphs with billions of vertices and edges. For those familiar with DSE
Cluster Migration - Keeping simple things simple I often get asked about the different ways to move data across DSE clusters (prod to qa, old cluster to new cluster, multi-cluster ETL). There are different options for these ranging from custom
C* schema changes and compatible types All the schema operations that can be done in c* are done without downtime. You should limit these actions as a best practice to 1 client (not multiple concurrent clients) to avoid schema
On Cassandra Collections, Updates, and Tombstones update I was chatting with a user today who referenced this old post. Most of it is still relevant but sstable2json is no longer supported in modern c*. The new tool is sstabledump.
Tuning DSE Search - Indexing latency and query latency Introduction DSE offers out of the box search indexing for your Cassandra data. The days of double writes or ETL's between separate DBMS and Search clusters are gone. I have my cql table,
Things you didn't think you could do with DSE Search and CQL Intro CQL and DSE Search promise to make access to a lucene backed index scalable, highly avaliable, operationally simple, and user friendly. There have been a couple of developments in DSE 4.8
Minimizing DSE Search (solr) Indexes Intro / why? Search query performance depends on our ability to utilize the OS page cache effectively to keep search indexes hot. The smaller the size of your indexes, the easier it will be
Interpreting Cassandra Repair logs and leveraging the OpsCenter repair service Introduction to repairs and the Repair Service Cassandra repairs consist of comparing data from between replica nodes, identifying inconsistencies, and streaming the latest value for mismatched data. We can't compare an entire cassandra
cassandra Cassandra Deletes - Understanding Range Tombstones Cassandra Deletes : An Introduction In a distributed Database, replication is key for ensuring high availability and performance. Once data gets deleted from a node in Cassandra, having a good understanding of c* deletes
cassandra Using the Cassandra Data Modeler to Stress and Size C*/DSE Instances Summary The main drivers behind Cassandra performance are: Hardware Data Model Application specific design and configuration (quick link to the modeler Cassandra Data Modeler for those that are just looking for the tool)
Using Brian's cassandra-loader/unloader to migrate C* Maps for DSE Search compatibility Intro Using map collections in DSE Search takes advantage of dynamic fields in Solr for indexing. For this to work, every key in your map has to be prefixed with the name of
How to use tobert's effio Summary The most critical OS subsystem for the performance and stability of a database like Cassandra is disk. Tobert wrote an excellent go utility called effio that harnesses the power of fio and
Welcome Here's some things you may be interested in: Cassandra Data Modeler Matches OpsCenter Import/Export - The tool OpsCenter Import/Export - The Blog Post DataStax Startup Program